Your Ultimate Guide to 60 Python Libraries for Data Analysis and Science
Python reigns supreme in data science and analysis, thanks to its robust libraries. This guide outlines 60 widespread ones, categorised to enhance your data projects.

Python is consistently rated as one of the world's most popular programming languages. As of April 2024, it holds the top spot in the TIOBE Programming Community Index, a key measure of programming language popularity.
In the fields of data analysis and science, Python especially stands out due to its comprehensive capabilities, ease of use, and the strong community that supports and drives its growth. Its rich set of libraries and frameworks, specifically designed for data manipulation, analysis, and machine learning, makes it an indispensable tool for any data professional.
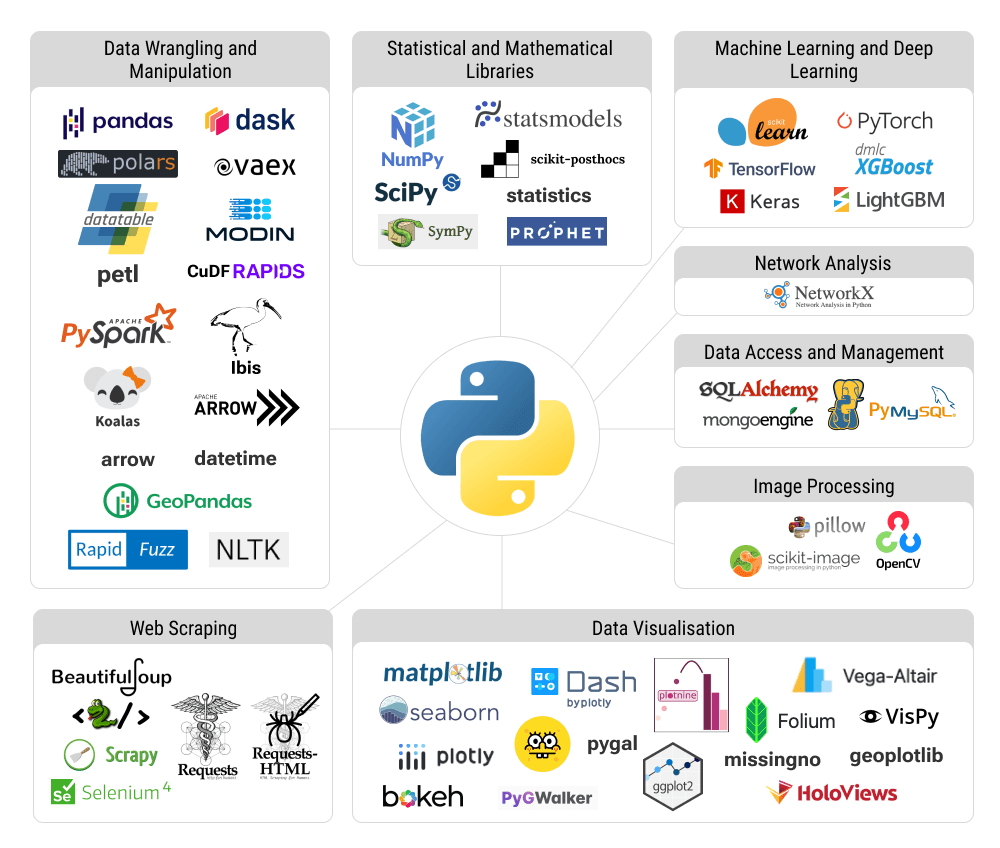
In order to better navigate the vast diversity of Python libraries, I have created a list of 60 the most widespread ones in the field and organised them into the following groups:
- Data wrangling and manipulation
- Statistical and mathematical libraries
- Machine learning and deep learning
- Network analysis
- Data visualisation
- Image processing
- Web scraping
- Data access and management.
Important Note: This list is not ranked based on any specific criteria.
Data Wrangling and Manipulation
Data wrangling and manipulation are critical phases in the data analysis and science workflow, involving the conversion of raw data into a more usable format. This process is fundamental to ensuring that data is clean, structured, and ready for in-depth analysis.
The difference in the definitions of data wrangling and manipulation, as well as comparative analysis of two most popular tools in this area, Pandas and Polars, you can find in my article “Data Wrangling and Manipulation in Python: Pandas vs. Polars”.
General Data Wrangling and Manipulation
1. Pandas: The primary library for data manipulation and analysis, offering data structures and operations for manipulating numerical tables and time series. [Documentation]
2. Polars: Provides high-performance DataFrames with features like lazy evaluation and parallel execution. [Documentation]
3. Datatable: Inspired by R's data.table, focuses on out-of-memory datasets and multi-threaded data processing. [Documentation]
4. Petl: Simplifies ETL (Extract, Transform, Load) processes, particularly useful for table-like data without requiring a predefined schema. [Documentation]
Scalable and Parallel Data Processing
5. Dask: Enables parallel computing, making it possible to work with very large datasets by breaking computations into smaller pieces. [Documentation]
6. Modin: Aims to speed up Pandas operations by parallelising tasks across all available CPU cores, using Dask or Ray as a backend. [Documentation]
7. Vaex: Specialises in processing extremely large datasets efficiently with out-of-core DataFrames. [Documentation]
8. CuDF: A component of the RAPIDS ecosystem providing GPU acceleration for DataFrame operations, suitable for high-performance data manipulation. [Documentation]
Spark-based Data Manipulation
9. PySpark: The Python API for Apache Spark, enabling scalable data processing and analytics on distributed computing systems. [Documentation]
10. Koalas: Enables Pandas DataFrame operations in Apache Spark, facilitating big data processing on distributed systems. [Documentation]
Advanced Data Architecture and Querying
11. PyArrow (Apache Arrow): Provides a cross-language development platform for in-memory data, enhancing data interoperability and efficiency. [Documentation]
12. Ibis: Facilitates working with big data in a Pandas-like manner, translating Python code into database queries. Designed for simplifying complex data manipulations and producing cleaner code. [Documentation]
Specialised Data Manipulation: Date and Time
13. Arrow: Offers a sensible and human-friendly approach to creating, manipulating, formatting and converting dates, times and timestamps. [Documentation]
14. Datetime: Provides functions to manipulate dates and times, including time parsing, formatting, and arithmetic. [Documentation]
Specialised Data Manipulation: Spatial Data
15. Geopandas: Extends Pandas for working with spatial data, integrating with other libraries like Shapely for geometric operations. [Documentation]
Specialised Data Manipulation: Text and String
16. RapidFuzz (ex. FuzzyWuzzy): Supports string matching and similarity comparisons, useful in data cleaning and deduplication. [Documentation]
17. NLTK: Primarily for natural language processing, but also includes capabilities for text manipulation and cleaning. [Documentation]
Statistical and Mathematical Libraries
Core Numerical and Scientific Computing
18. Numpy: Fundamental package for scientific computing with Python, offering powerful n-dimensional array objects. [Documentation]
19. SciPy: Builds on Numpy, providing additional modules for optimisation, linear algebra, integration, and more. [Documentation]
20. SymPy: A Python library for symbolic mathematics. It aims to become a full-featured computer algebra system (CAS) while keeping the code as simple as possible in order to be comprehensible and easily extensible. [Documentation]
Statistical Modelling and Analysis
21. Statsmodels: Used for statistical modelling and hypothesis testing. Provides classes and functions for the estimation of many different statistical models. [Documentation]
22. SciKit-PostHocs: Provides post-hoc tests for multiple comparisons. [Documentation]
23. Statistics: Provides functions to calculate mathematical statistics of numerical data. [Documentation]
Time Series Forecasting
24. Prophet (Facebook Prophet): Tool designed for forecasting with daily observations that display patterns on different time scales. [Documentation]
Machine Learning and Deep Learning
General Machine Learning
25. Scikit-learn: Mainly used for machine learning but includes tools for data preprocessing, such as scaling and encoding features. [Documentation]
Deep Learning Frameworks
26. TensorFlow: Open-source platform for machine learning and deep learning developed by Google. [Documentation]
27. Keras: High-level neural networks API, capable of running on top of TensorFlow, Microsoft Cognitive Toolkit, or Theano. [Documentation]
28. PyTorch: Open-source machine learning library developed by Facebook, known for its flexibility and dynamic computational graph. [Documentation]
Gradient Boosting Machines
29. XGBoost: Stands for eXtreme Gradient Boosting; it is a highly optimised, scalable, and fast implementation of gradient boosting that is widely used in machine learning competitions and practical applications. [Documentation]
30. LightGBM: A fast, distributed, high-performance gradient boosting framework based on decision tree algorithms, used for many machine learning tasks. It is designed to be distributed and efficient with lower memory usage. [Documentation]
Network Analysis
31. NetworkX: Package for the creation, manipulation, and study of the structure, dynamics, and functions of complex networks. [Documentation]
Data Visualisation
General-Purpose Plotting
32. Matplotlib: A comprehensive library for creating static, animated, and interactive visualisations in Python. It's highly customisable and serves as the foundation for many other plotting libraries. [Documentation]
33. Seaborn: Built on top of Matplotlib, Seaborn simplifies the creation of beautiful and informative statistical graphics. It's particularly well-suited for visualising complex datasets. [Documentation]
Interactive Web-based Visualisation
34. Plotly: A library that enables the creation of interactive, publication-quality graphs. It supports a wide range of chart types and can be used in Python scripts, web application servers, and Jupyter notebooks. [Documentation]
35. Bokeh: Designed for creating interactive plots and dashboards that can be embedded in web applications. Bokeh excels at building complex statistical plots with interactivity and web-friendly output. [Documentation]
36. Dash: Developed by Plotly, Dash is more of a framework for building analytical web applications with Python (no JavaScript required). It's particularly suited for creating interactive visualisations and dashboards. [Documentation]
37. Pyecharts: Generates Echarts (a powerful, interactive charting and visualisation library for browsers) charts in a Pythonic way. It is especially useful for data analysts who need to create intricate and interactive charts in web reports. [Documentation]
38. PyGWalker: Integrates Jupyter Notebook with Graphic Walker, an open-source alternative to Tableau. It allows data scientists to visualise / clean / annotates the data with simple drag-and-drop operations and even natural language queries. [Documentation]
SVG and Lightweight Plotting
39. Pygal: A dynamic SVG charting library that produces scalable vector graphics (SVG) charts. It's particularly suited for smaller datasets and can produce highly readable and easily customisable charts. [Documentation]
Grammar of Graphics Libraries
Libraries in this group are based on the principles of "The Grammar of Graphics," which are ports of the popular ggplot2 library in R. They are useful for those familiar with ggplot2 or who prefer its approach to visualisation.
40. Plotnine: Allows users to build complex visualisations layer by layer, making it ideal for exploratory data analysis with a high degree of customisation. [Documentation]
41. ggplot (ggpy): Provides a framework for creating a wide range of statistical plots with a syntax that is declarative and easy to understand. [Documentation]
While both Plotnine and ggplot (ggpy) aim to bring the power and flexibility of ggplot2 to Python, Plotnine is generally considered the more robust and reliable choice. It offers greater functionality, better performance, and has a more active development path
Specialised Visualisation
42. Altair: A declarative statistical visualisation library that's user-friendly and designed for simplicity. Altair's API is straightforward, making it a great choice for beginners in data visualisation. [Documentation]
43. Folium: Builds on the data wrangling strengths of Python and the mapping strengths of the Leaflet.js library. It allows users to manipulate data in Python, then visualise it in on an interactive Leaflet map via folium. [Documentation]
44. Missingno: Provides a suite of visualisations to understand the distribution of missing data within a dataset, helping to strategise how best to handle it. [Documentation]
45. Holoviews: Designed to make data analysis and visualisation seamless and simple. It lets you annotate your data with a small amount of metadata that can be very useful when you need to visualise it. [Documentation]
46. VisPy: A high-performance scientific visualisation library in Python, based on OpenGL. It seeks to provide visualisations that are both beautiful and fast, making it suited for real-time data visualisation. [Documentation]
47. Geoplotlib: A toolbox for creating maps and plotting geographical data. It allows you to easily create layered maps for data visualisation, particularly useful for data with geographical components. [Documentation]
Image Processing Libraries
48. Pillow (PIL Fork): A fork of PIL (Python Image Library) that adds some user-friendly features. [Documentation]
49. OpenCV: Stands for Open Source Computer Vision Library, a highly optimised library focused on real-time applications. It supports a wide range of applications in machine vision, including motion tracking, facial recognition, and object detection. [Documentation]
50. Scikit-image: Part of the SciPy ecosystem, scikit-image is geared towards image processing for scientific and analytical applications. It is built on NumPy and provides a comprehensive set of algorithms for image processing. [Documentation]
Data Access and Management
51. SQLAlchemy: The Python SQL toolkit and Object-Relational Mapping (ORM) library that gives application developers the full power and flexibility of SQL. [Documentation]
52. PyMySQL: PyMySQL is a pure-Python MySQL client library, which allows Python to interface with a MySQL database server in a straightforward fashion. [Documentation]
53. Psycopg2: Psycopg is the most popular PostgreSQL database adapter for the Python programming language. It is implemented in C and provides a means for Python code to interact with PostgreSQL in an efficient and straightforward manner. [Documentation]
54. MongoEngine: MongoEngine is an ORM-like layer on top of PyMongo, which is a library for working with MongoDB from Python. It provides a higher abstraction than PyMongo to work with MongoDB documents as if they were Python objects. [Documentation]
Web Scraping
55. Beautiful Soup: Eases web scraping by parsing HTML and XML, facilitating information extraction from web content. [Documentation]
56. Lxml: While technically an XML and HTML parsing library, lxml is incredibly fast and feature-rich, making it suitable for high-performance scraping. It provides support for XPath and XSLT, making it powerful for scraping tasks that require parsing complex HTML documents. [Documentation]
57. Scrapy: An open-source and collaborative framework for extracting the data you need from websites. [Documentation]
58. Selenium: Initially created for automating web browsers, Selenium can be used for scraping dynamic content rendered by JavaScript. It allows you to automate browser actions such as clicking and scrolling, which can be very useful for interacting with web pages to access the data. [Documentation]
59. Requests: A simple HTTP library for Python, built for human beings to interact with the internet. [Documentation]
60. Requests-HTML: Developed by the creator of the requests library, Requests-HTML is designed for HTML parsing for humans. It combines the capabilities of requests for HTTP sessions with the best parts of html parsing libraries. It's especially good at handling JavaScript-based pages. [Documentation]
Final Thoughts
With 60 libraries available, it's impossible to use all of them simultaneously for one specific task. You can find steps and practical tips on how to select the most suitable Python library for your data analysis or science project in my article on this topic. Don't miss it.
REFERENCES
- TIOBE Software BV. "TIOBE Index for April 2024." TIOBE Software BV, n.d., www.tiobe.com/tiobe-index. Accessed 18 April 2024.


