How to Choose the Right Python Library for Your Data Project?
Discover practical tips and tools to pinpoint the right Python library for your data project, ensuring optimal results and efficiency.

Nowadays, there is a plethora of Python libraries and frameworks that equip data analysts and scientists with the necessary tools to handle specific tasks effectively, from data preprocessing and analysis to model building and data visualisation.
In my previous article, I created a categorised list of the 60 most widespread Python libraries for data analysis and science. However, this is still a large number, and you can’t use all of them simultaneously to solve one specific task. Choosing the right Python library can significantly impact the efficiency and success of your work.
Which library should you then focus on? What are the criteria for selection?
To answer these questions, this article provides steps and practical tips on how to select the most suitable Python library for a data analysis or science project:
- Define your requirements
- Consider the library's specialty
- Evaluate the library’s popularity
- Check documentation and community support
- Check recent updates and maintenance
- Review features and capabilities
- Try out the library.
At fist glance, this may seem very simple and general, but the difficulties begin when it comes to practice. Continue reading to avoid these challenges. You will find useful maps, schemas, statistics, and practical advice that will guide you in choosing the right tools, making your journey in data analysis and science both productive and innovative.
#1: Define Your Requirements
Before diving into a library, clearly define what you need:
- Are you working primarily with numerical data, textual data, or images?
- Will you need to perform heavy statistical analysis, machine learning, or just simple data manipulation and visualisation?
- What tools are you currently using, and do you need any integration with them?
- What is the size of your data, and what are your performance requirements?
Understanding your specific requirements will help narrow down the library choices to those best suited for your tasks.
#2: Consider the Library's Specialty
Each Python library is typically designed with specific tasks in mind. For example:
- Pandas is excellent for data manipulation and analysis of tabular data.
- Scikit-learn is ideal for machine learning.
- OpenCV and scikit-image are perfect for image processing tasks.
Based on library’s specialty and its use cases across various stages of data analysis and science projects, I created an at-a-glance map that guides the selection process across 60 widespread libraries in the field:
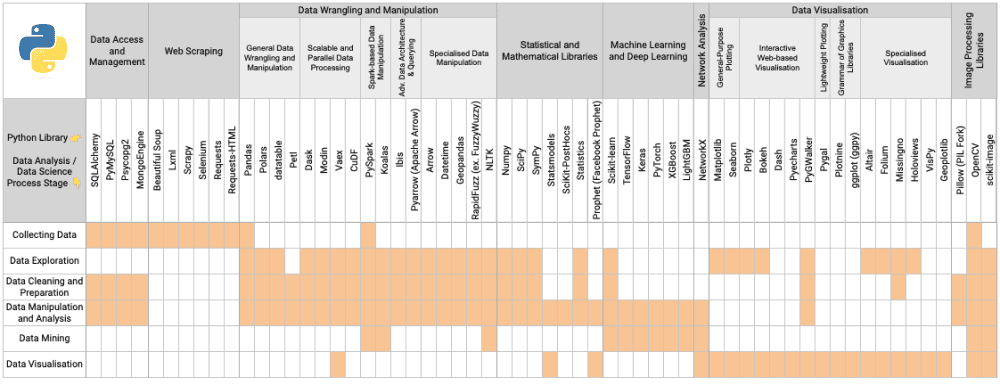
#3: Evaluate the Library’s Popularity
Popular libraries are more likely to be maintained and updated regularly, which is crucial in the fast-evolving field of data science. A large user base typically indicates a reliable and tested tool.
The popularity of a Python library can be evaluated in three aspects:
- Popularity among users (download statistics, number of stars on the GitHub platform)
- Popularity in the developer community (number of GitHub forks, contributors, commits, releases)
- Recognition from reputable organisations and industry experts (awards and recognitions from technology events, expert reviews, and testimonials).
In this article, I have focused on the first two aspects: popularity among users and popularity within the developer community. To provide statistics for 60 Python libraries used in data analysis and science, I collected data on monthly downloads, GitHub stars, and forks:
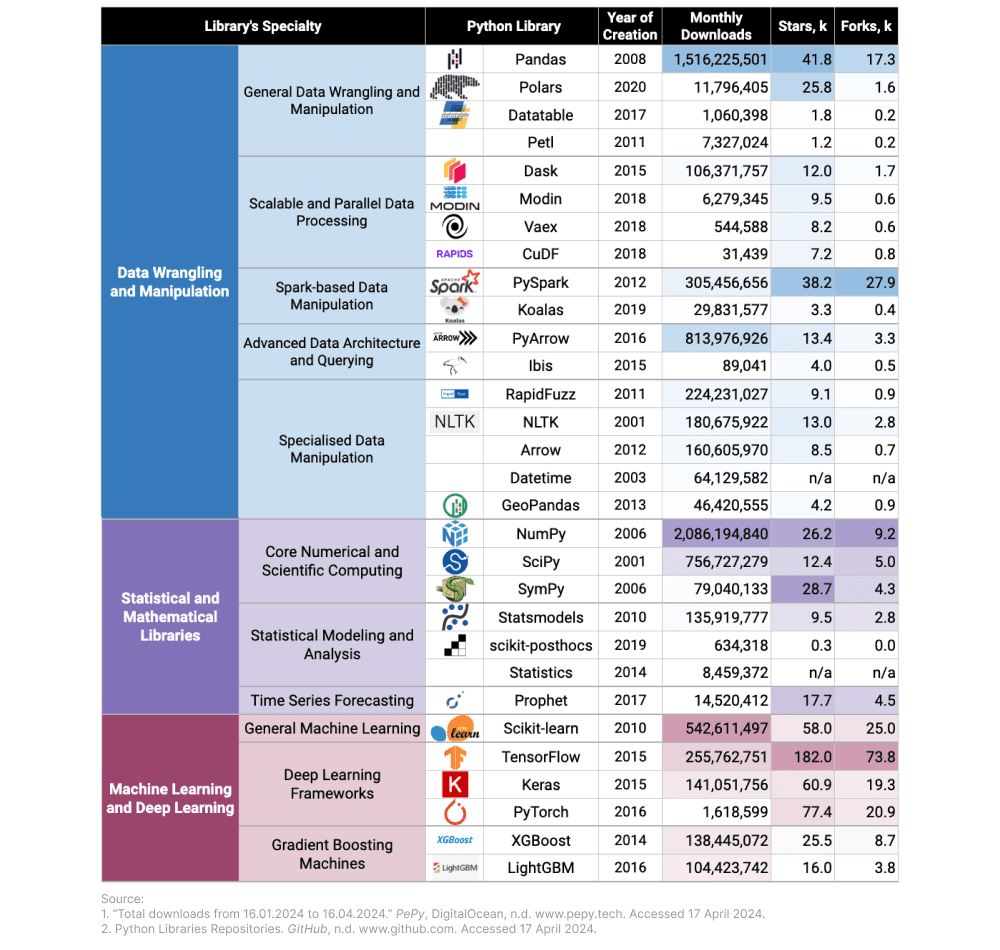
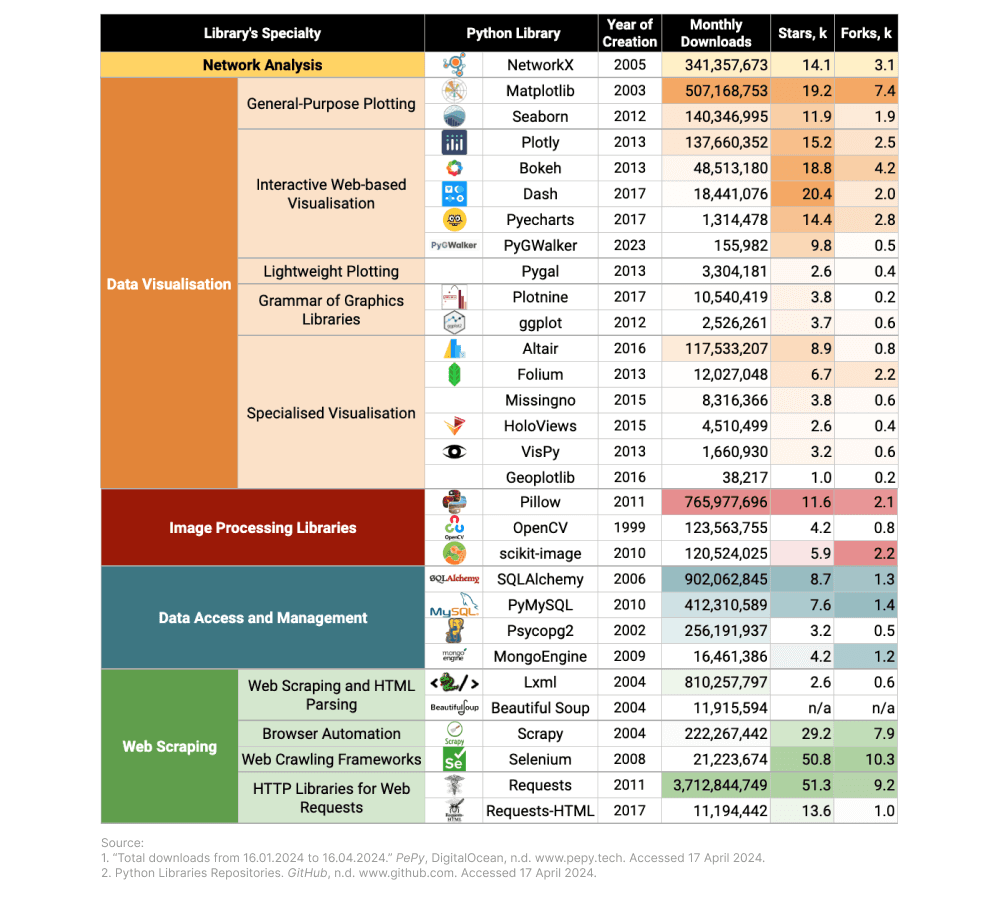
- A high download count suggests that the library is widely used. There is also the possibility to observe trends over time to determine if the library is gaining or losing popularity. Platforms like PyPI (Python Package Index) and pepy.tech provide download statistics for Python packages.
- A higher number of stars typically indicates that a library is widely appreciated within the community, while forks indicate that people are actively using and potentially enhancing the library. These numbers can be found on the platforms and websites like GitHub or libraries.io.
#4: Check Documentation and Community Support
A well-documented library with active community support can drastically reduce your learning curve and troubleshooting time. Libraries with extensive documentation, tutorials, and active forums or discussion groups ensure that you can find help when you encounter problems.
- Good documentation is often indicative of a project's quality and popularity. Well-documented libraries are easier to use and therefore more likely to be adopted.
- Look at the size and activity of the community around the library. A vibrant community often has active forums, frequent meetups, or dedicated conferences. Large communities can provide better support and are more likely to continue maintaining the library.
- See if the library is frequently mentioned or recommended in educational resources and professional publications. Frequent citations can indicate that a library is trusted and recommended within the industry.
Examples include libraries like TensorFlow and PyTorch, which not only have comprehensive documentation but also massive community support.
#5: Check Recent Updates and Maintenance
A library that is actively maintained and regularly updated is crucial, especially to keep up with new trends and improvements in data science methodologies. Check the library’s repository for recent commits, releases, and the responsiveness of maintainers to issues and pull requests.
#6: Review Features and Capabilities
If you followed the tips in the previous steps, you now have a list of potential top libraries that meet your basic criteria. Thus, it’s time to compare their features and capabilities. There are three key aspects to consider:
- Functionality: Assess whether the library has all the features you need based on its documentation.
- Performance and Scalability: Some libraries are better suited for large datasets or distributed computing than others. If your work involves large volumes of data, consider performance-focused libraries like Dask or Vaex for handling big data sets, or PySpark for distributed data processing. The performance benchmarks available can be evaluated in the library's documentation or through independent reviews.
- Compatibility with Other Tools: Ensure the library works well with other tools in your data stack. For instance, if you use Jupyter Notebooks extensively, ensure that your chosen library integrates smoothly with Jupyter. Similarly, if your project involves a web framework like Django or Flask, check for compatibility or existing integrations.
#7: Try Out the Library
Finally, the best way to know if a library suits your needs is to try it out. Implement a small pilot project or a few test scripts to get a feel for the library’s API and see if it fits your working style and meets the project requirements.
Final Thoughts
Choosing the right Python library requires a balance of statistics, professional judgement, and curiosity. By following these tips, you can make an informed decision when selecting the library that best fits your data analysis and data science projects.
REFERENCES
- "Home Page." Pepy, no date, www.pepy.tech.
- "Home Page." PyPI Stats, no date, www.pypistats.org.
- "Home Page." Python Package Index, no date, www.pypi.org.
- "Home Page." GitHub, no date, www.github.com
- "Home Page." Libraries.io, no date, www.libraries.io.
- "How to Evaluate the Quality of Python Packages." Real Python, no date, www.realpython.com/python-package-quality/.


